
شیمی تولیدی با هوش مصنوعی این پتانسیل را دارد که نحوه رویکرد دانشمندان به کشف و توسعه دارو، سلامت، و علم و مهندسی مواد را متحول کند. به جای طراحی دستی مولکولها با "شهود شیمیایی" یا غربالگری میلیونها ماده شیمیایی موجود، محققان میتوانند شبکههای عصبی را برای پیشنهاد ساختارهای مولکولی جدید متناسب با خواص مورد نظر آموزش دهند. این قابلیت فضاهای شیمیایی وسیعی را باز میکند که قبلاً امکان کاوش سیستماتیک آنها وجود نداشت.
در حالی که برخی از موفقیتهای اولیه نشان دهنده این وعده است که هوش مصنوعی تولیدی میتواند با پیشنهاد راه حلهای خلاقانهای که شیمیدانان ممکن است در نظر نگرفته باشند، نوآوری را تسریع کند، این پیروزیها تنها آغاز راه است. هوش مصنوعی تولیدی هنوز یک راه حل جادویی برای طراحی مولکولی نیست، و تبدیل مولکولهای پیشنهادی هوش مصنوعی به دنیای واقعی اغلب
این شکاف بین طرحهای مجازی و تأثیر دنیای واقعی، چالش اصلی امروز در طراحی مولکولی مبتنی بر هوش مصنوعی است. مدلهای شیمی محاسباتی تولیدی به بازخورد تجربی و شبیهسازیهای مولکولی نیاز دارند تا تأیید کنند که مولکولهای طراحیشده آنها پایدار، قابل سنتز و کاربردی هستند. مانند خودروهای خودران، هوش مصنوعی باید با دادههای رانندگی دنیای واقعی یا شبیهسازیهای با دقت بالا آموزش داده و اعتبارسنجی شود تا در جادههای غیرقابل پیشبینی حرکت کند. همانطور که در بهروزرسانی جدید طرح NVIDIA BioNeMo برای غربالگری مجازی یکی از رویکردهای قدرتمند برای اتصال طرحهای هوش مصنوعی به واقعیت، از طریق اوراکلها (همچنین به عنوان توابع امتیازدهی شناخته میشوند) است. در طراحی مولکولی تولیدی، یک اوراکل یک مکانیسم بازخورد است - یک آزمایش یا ارزیابی که به ما میگوید یک مولکول پیشنهادی در رابطه با یک نتیجه مطلوب، اغلب یک خاصیت مولکولی یا تجربی (به عنوان مثال، قدرت، ایمنی و امکان سنجی) چگونه عمل میکند. این اوراکل میتواند: مبتنی بر آزمایش: یک سنجش که میزان اتصال یک مولکول دارویی طراحی شده توسط هوش مصنوعی به یک پروتئین هدف را
اندازه گیری میکند. این اوراکل مبتنی بر محاسبات با استفاده از محاسبات با کیفیت بالا (مانند شبیهسازیهای دینامیک
مولکولی) است که یک ویژگی را به طور دقیق پیش بینی میکند، مانند یک روش انرژی آزاد برای محاسبه انرژی اتصال (اینکه یک دارو
چقدر محکم در جیب یک آنزیم قرار میگیرد) یا یک محاسبه شیمی کوانتومی از پایداری یک ماده. اینها جایگزینهای درون
سیلیکونی برای آزمایشها هستند زمانی که آزمایش آزمایشگاهی کند، پرهزینه است یا زمانی که ارزیابی در مقیاس بزرگ مورد
نیاز است. در عمل، محققان اغلب از یک استراتژی لایه ای استفاده میکنند که در آن اوراکلهای ارزان و با توان عملیاتی بالا (مانند
غربالگریهای محاسباتی سریع) سیل مولکولهای تولید شده توسط هوش مصنوعی را فیلتر میکنند. سپس، امیدوارکنندهترین نامزدها با
اوراکلهای با دقت بالاتر (شبیهسازیهای دقیق یا آزمایشهای واقعی) ارزیابی میشوند. این امر با تمرکز کار آزمایشگاهی
گران قیمت تنها بر روی پیشنهادات برتر هوش مصنوعی، در زمان و منابع صرفه جویی میکند. طرح NVIDIA BioNeMo برای غربالگری مجازی تولیدی (شکل 1) نمونهای از این است: از شبه کد زیر پیروی کنید تا یک خط لوله تولید و بهینه سازی مولکولی تکراری را با استفاده از NVIDIA GenMol NIM پیاده سازی کنید. این فرایند شامل تولید مولکولها از یک کتابخانه قطعه،
ارزیابی آنها با یک اوراکل، انتخاب نامزدهای برتر، تجزیه آنها به قطعات جدید و تکرار چرخه است. از شبه کد زیر پیروی کنید تا یک فرایند تولید مولکولی تکراری و هدایت شده توسط اوراکل را با استفاده از MolMIM NIM پیاده سازی کنید. این رویکرد شامل تولید مولکولها، ارزیابی آنها با یک
اوراکل، انتخاب نامزدهای برتر و اصلاح فرایند تولید بر اساس بازخورد اوراکل است (کد نمونه نوت بوک را در اینجا
ببینید). ادغام اوراکلها - مکانیسمهای بازخورد تجربی و مبتنی بر محاسبات - به طور اساسی طراحی دارو را تغییر میدهد. محققان
میتوانند با ایجاد یک حلقه مداوم بین مدلهای تولیدی و اعتبار سنجی دنیای واقعی، از تولید مولکول نظری فراتر رفته و به
نامزدهای دارویی عملی، قابل سنتز و کاربردی برسند. این رویکرد آزمایشگاهی در حلقه امکان پذیر میکند: همانطور که مدلهای هوش مصنوعی و سیستمهای اوراکل پیشرفتهتر میشوند، ما به عصری نزدیک میشویم که در آن هوش مصنوعی و
علم تجربی با هم تکامل مییابند و باعث پیشرفت در طراحی دارو میشوند. با ادغام اوراکلهای با کیفیت بالا، شکاف بین طراحی
مولکولی مجازی و موفقیت دنیای واقعی همچنان کاهش مییابد و امکانات جدیدی را برای پزشکی دقیق و فراتر از آن باز میکند.اوراکلها: بازخورد از آزمایشها و شبیهسازیهای با دقت بالا
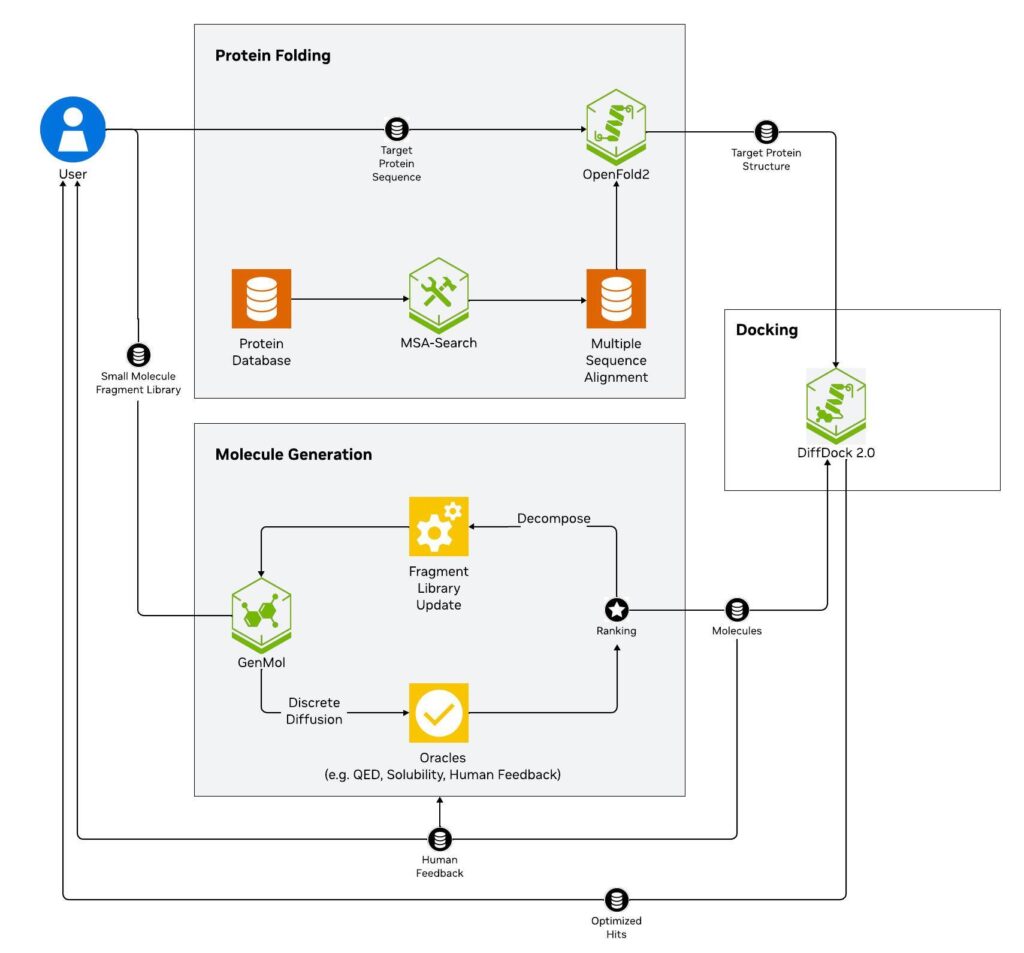
اوراکلها در طراحی مولکولی مبتنی بر قطعه
# Import necessary modules
from genmol import GenMolModel, SAFEConverter # Hypothetical GenMol API
from oracle import evaluate_molecule # Hypothetical oracle function
from rdkit import Chem
from rdkit.Chem import AllChem, BRICS
import random
# Define hyperparameters
NUM_ITERATIONS = 10 # Number of iterative cycles
NUM_GENERATED = 1000 # Number of molecules generated per iteration
TOP_K_SELECTION = 100 # Number of top-ranked molecules to retain
SCORE_CUTOFF = -0.8 # Example binding affinity cutoff for filtering
# Initialize GenMol model
genmol_model = GenMolModel()
# Load initial fragment library (list of SMILES strings)
with open('initial_fragments.smi', 'r') as file:
fragment_library = [line.strip() for line in file]
# Iterative molecule design loop
for iteration in range(NUM_ITERATIONS):
print(f"Iteration {iteration + 1} / {NUM_ITERATIONS}")
# Step 1: Generate molecules using GenMol
generated_molecules = []
for _ in range(NUM_GENERATED):
# Randomly select fragments to form a SAFE sequence
selected_fragments = random.sample(fragment_library, k=random.randint(2, 5))
safe_sequence = SAFEConverter.fragments_to_safe(selected_fragments)
# Generate a molecule from the SAFE sequence
generated_mol = genmol_model.generate_from_safe(safe_sequence)
generated_molecules.append(generated_mol)
# Step 2: Evaluate molecules using the oracle
scored_molecules = []
for mol in generated_molecules:
score = evaluate_molecule(mol) # Example: docking score, ML predicted affinity
scored_molecules.append((mol, score))
# Step 3: Rank and filter molecules based on oracle scores
scored_molecules.sort(key=lambda x: x[1], reverse=True) # Sort by score (higher is better)
top_molecules = [mol for mol, score in scored_molecules[:TOP_K_SELECTION] if score >= SCORE_CUTOFF]
print(f"Selected {len(top_molecules)} high-scoring molecules for next round.")
# Step 4: Decompose top molecules into new fragment library
new_fragment_library = set()
for mol in top_molecules:
# Decompose molecule into BRICS fragments
fragments = BRICS.BRICSDecompose(mol)
new_fragment_library.update(fragments)
# Step 5: Update fragment library for next iteration
fragment_library = list(new_fragment_library)
print("Iterative molecule design process complete.")
اوراکلها در تولید مولکولی کنترل شده
# Import necessary modules
from molmim import MolMIMModel, OracleEvaluator # Hypothetical MolMIM and Oracle API
import random
# Define hyperparameters
NUM_ITERATIONS = 10 # Number of iterative cycles
NUM_GENERATED = 1000 # Number of molecules generated per iteration
TOP_K_SELECTION = 100 # Number of top-ranked molecules to retain
SCORE_CUTOFF = 0.8 # Example oracle score cutoff for filtering
# Initialize MolMIM model and Oracle evaluator
molmim_model = MolMIMModel()
oracle_evaluator = OracleEvaluator()
# Iterative molecular design loop
for iteration in range(NUM_ITERATIONS):
print(f"Iteration {iteration + 1} / {NUM_ITERATIONS}")
# Step 1: Generate molecules using MolMIM
generated_molecules = molmim_model.generate_molecules(num_samples=NUM_GENERATED)
# Step 2: Evaluate molecules using the oracle
scored_molecules = []
for mol in generated_molecules:
score = oracle_evaluator.evaluate(mol) # Returns a score between 0 and 1
scored_molecules.append((mol, score))
# Step 3: Rank and filter molecules based on oracle scores
scored_molecules.sort(key=lambda x: x[1], reverse=True) # Sort by score (higher is better)
top_molecules = [mol for mol, score in scored_molecules[:TOP_K_SELECTION] if score >= SCORE_CUTOFF]
print(f"Selected {len(top_molecules)} high-scoring molecules for next round.")
# Step 4: Update MolMIM model with top molecules
molmim_model.update_model(top_molecules)
print("Iterative molecular design process complete.")
اوراکلها را برای طراحی دارو امتحان کنید